Actualidad
Accidentes de tránsito en el Gran Santiago 2019
En 2019, Marcelo Rovai publicó en towardsdatascience un trabajo muy interesante:
How safe are the streets in Santiago?
Para acceder al artículo entero, abrirlo en navegación privada (modo incógnito).

Nota: Si quieren aprender más de programación o Data Science, les recordamos que tenemos convenios con nuestros aliados Le Wagon Chile. Pueden ir a este link para más información.
Todo el trabajo de Marcelo Rovai está disponible en una carpeta GitHub. Nosotros quisimos reproducirlos, y aprovechamos la oportunidad para:
- Actualizar el trabajo con los últimos datos de siniestros del CONASET [2];
- Usar GeoPackage para disminuir el peso de los datos espaciales;
- Agregar la infraestructura necesaria para que el código sea 100% distribuible. Para esto, se creó una imagen Docker.
Nuestra versión del proyecto está disponible en:
https://github.com/YachayData/calles_santiago
Siéntanse libres de usar este código y mejorarlo.
Uno de los mapas del trabajo que encontramos muy llamativo es la densidad de siniestros de tránsito en el Gran Santiago:
Sobre Docker
Para aporta nuestro granito de arena, y que aprendan algo hoy, queremos presentar Docker. Si les gusta programar, es un software muy importante para tener código reproducible y distribuible. Para descargar Docker, hacer clic en este enlace.

Para este proyecto, Docker es muy útil porque permite replicar simplemente (de hecho con un comando único) los resultados del proyecto. Basta con correr:
docker run -p 8888:8888 pescapil/geostreeten un terminal. Este comando:
- Descarga la imagen del contenedor pescapil/geostreet;
- Corre este contenedor y abre Jupyter-Notebook para reproducir los resultados.
Para simplificar, un contenedor es como si uno tuviera un computador independiente, con su propio sistema operativo (Ubuntu, Windows), su memoria, sus librerías…
Es muy potente porque el proyecto calles_santiago usa varias librerías tales como geopandas, que pueden ser difíciles de instalar. Además, el proyecto funciona con versiones específicas de las librerías (dependencias), y a veces puede resultar muy difícil correr el código.
Si tienen preguntas, nos pueden inscribir en Instagram, o a contacto@yachaygroup.com.

Hoy quisimos hablar un poco de Web Scraping. ¿De qué se trata?
El Web Scraping agrupa los métodos de extracción de datos en la web:
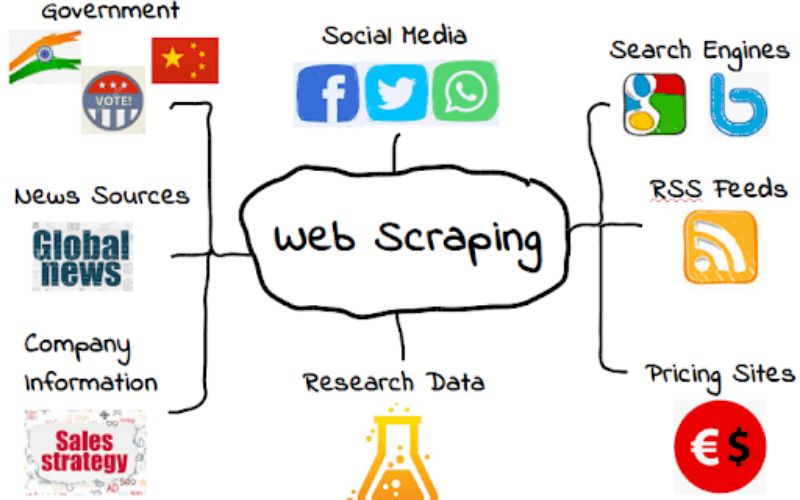
Los sitios web tienen mucha información relevante. A veces, esta puede ser exportada directamente como Excel .xlsx, un archivo separado por comas .csv u otras extensiones comunes. Como ejemplo, mencionamos a Our World In Data, que está hecho para ser de uso simple. En un par de clics, uno puede generar distintas visualizaciones y acceder a los datos en varios formatos.
Otras veces, se ponen a disposición APIs, que permiten recuperar la información directamente. Por ejemplo, Uber tiene una (ver ahí). Con una línea de código, uno puede enviar solicitudes “requests”, y obtener información de tráfico, de precios, entre otros.
Pero, en la mayoría de los casos, el sitio no está hecho para que uno pueda recolectar información. Ahí llega el mundo del Web Scraping.
Además, el Web Scraping está muy relacionado con el manejo de tareas repetitivas. La misma pregunta vuelve siempre: ¿Vale la pena armar código para automatizar la recuperación de datos? ¿O es mejor hacerlo manual?
La herramientas de Web Scraping se justifican cuando la recolección de datos manual requeriría demasiado recursos (tiempo, energía…). Como muchas veces, esto depende de trade-offs.
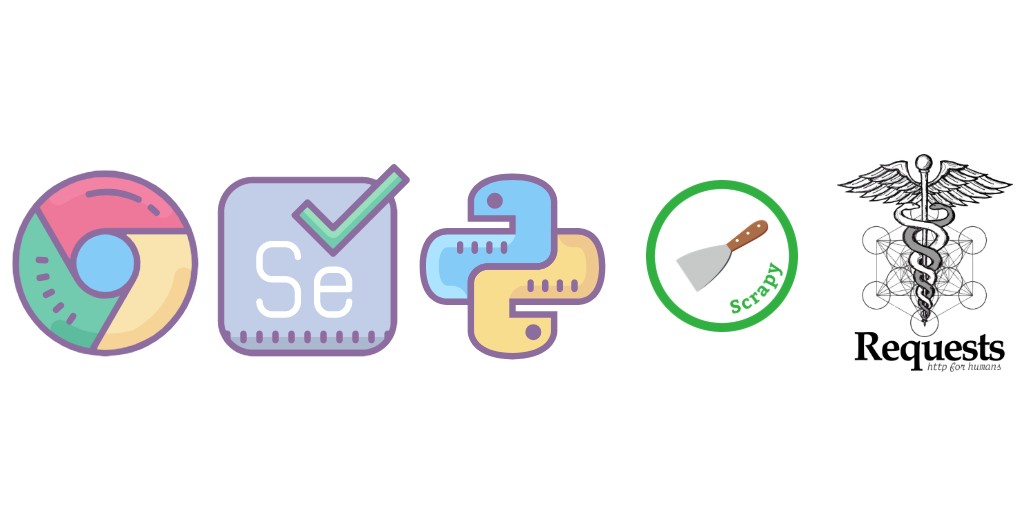
Sigamos un poco con las herramientas disponibles. Dependiendo del sitio web scrapeado, uno puede usar distintas librerías. En general, se usan librerías de Python para hacer Web Scraping (también existen librerías para Node.js).
Las librerías que más se usan son requests, selenium, beautifulsoup o scrapy. Permiten navegar en las páginas web, y recuperar la información deseada, al acceder a los elementos del html.
Si necesitas ayuda para armar este tipo de herramientas, nos puedes escribir a contacto@yachaygroup.com. Si quieres aprender a programar en Python, inscríbete a los cursos Le Wagon (contáctanos si quieres beneficiar del descuento 15% Yachay por correo, o a nuestra página Instagram).